Schon vor Längerem habe ich ja bereits angekündigt, dass Freelenz an einem ebenso spannenden wie innovativen Projekt werkelt. Worum es sich dabei in etwa handelt, werden wiederkehrende Besucher wohl bereits obigem Plakat entnommen haben, das seit einiger Zeit an der Tapete hängt. Worum es sich konkret handelt, will ich hier und jetzt verraten. Schließlich sind es nur noch knapp zwei Wochen bis zum offiziellen Start.
Immoment ist eine regionale, semantische Suchmaschine für Immobilieninserate. Regional, weil auf Österreich beschränkt. Semantisch, weil Immoment bestimmte Eckdaten einer Immobilienanzeige im Internet erkennen und verwerten kann, wie zum Beispiel die Wohnfläche, den Preis, ob es sich um ein Miet- oder Kaufobjekt handelt, PLZ/Ort, etc. Nach diesen Kriterien kann eben auch auf Immoment gesucht/gefunden/sortiert werden.
Außerdem lässt das Web 2.0 herzlich grüßen. Durch den verstärkten Einsatz von Ajax wird das ebenso praktische wie innovative Konzept der Livesuche verwirklicht. Will heißen: Hier ein paar Stichworte eintippen, dort den Preisschieber bewegen, dann vielleicht noch ein paar Kästchen ankreuzen – die Suchergebnisse folgen prompt und auf dem Fuße. Und das Beste daran: Die Parameter können laufend verändert werden. Kein mühsames Durcharbeiten mehrerer Webformulare, kein mehrfaches Zurückklicken bei erfolgloser Suche.
Bei Immoment fühlt sich das Suchen eher an wie ein Eichen und Justieren, ein Frage-und-Antwort-Spiel, ein Dialog mit der Datenbank, ein lebendiger Prozess, … okay, genug damit. ;-)
Konkret sieht das ungefähr folgendermaßen aus:
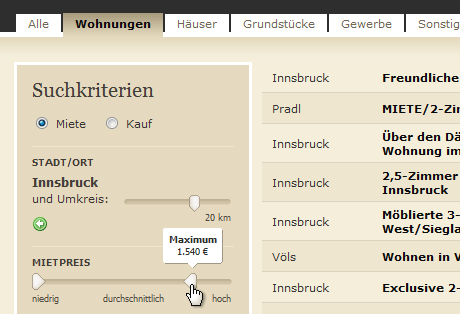
Links spielt die Musik, da werden die Suchkriterien eingestellt, also zum Beispiel wird eine Preisober- und -untergrenze festgelegt. Daneben erscheinen ruckzuck die Resultate. Feine Sache oder was?
Also, am 1. Februar ist es soweit! Inzwischen geht der Immobot fleißig um und indiziert Inserate. So um die 40.000 werden es zu Beginn sein, aber das ist noch stark ausbaufähig.